一个数据处理框架, 可从一个或多个源端将数据处理并同步至一个或多个目标端, 全配置化同步策略, 借助于SpringEL表达式, 支持强大的数据逻辑处理
项目监控页面地址: https://cygnus.ink/index
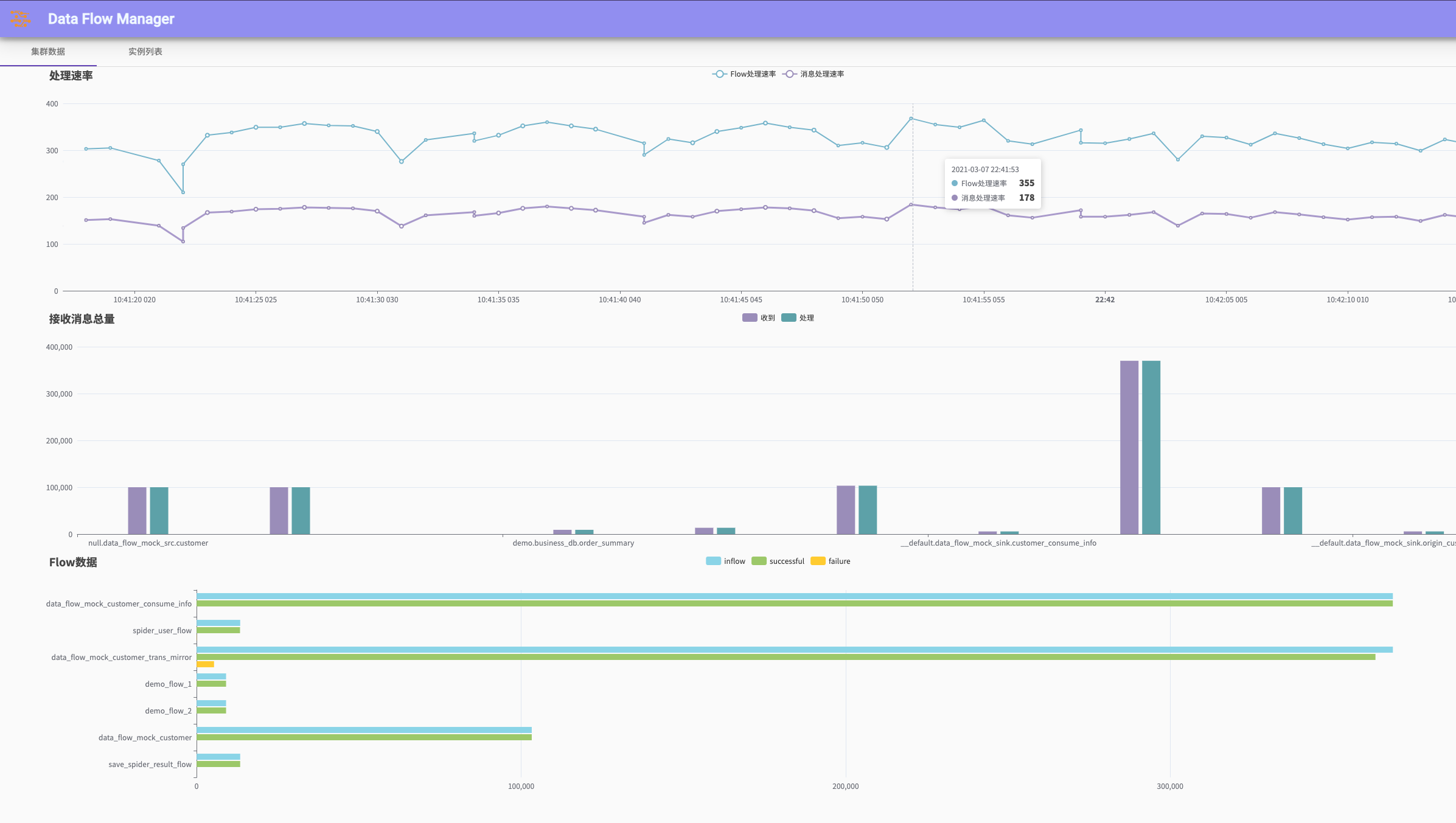
data-flow简单的后台管理页面,支持flow配置可视化查看以及编辑,同步速率监控等,点击右上角或左下角显示导航菜单(由于个人服务器性能原因(1C2G),当前的页面体验可能较差)
- data-flow-server模块基础功能开发
- data-flow-server模块
- 提供一个演示程序(data-flow-demo模块)
- 集群应用监控
- 前端模块(data-flow-view)开发
- 支持docker集群部署
- 增加Spark Streaming支持
- ......
- Java: 基于Java SE 8+ 开发
- MongoDB: 用于存储程序的配置文件, 或者也可自行实现配置的增删改方式
- Redis:用于集群管理
- Kafka: 若消息从kafka接入(例如canal, ogg等工具)或者需要写入目标为Kafka, 则需要配置kafka
- MySQL: 写入目标为MySQL时需要
- 其他: 若数据需要写入到Oracle, SQLServer, Rocket, Rabbit等存储介质时, 需要对应配置
该模块作为spring starter引入其他项目中, 可高度定制化
该模块将starter模块进行了包装, 可直接启动, 使用了默认的配置化数据处理方案
# 多数据源配置,
multi-data-source:
# 是否启用多数据源, 若项目不涉及数据库操作, 可为false
enable: true
# 数据源配置, 只支持hikari连接池
data-source:
hikari:
- pool-name: master # mysql连接池名称, 同时也是数据源名称, 在flow配置中通过此名称选择数据源, 不可重复
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/
password: 58603924715
username: root
connection-test-query: SELECT 1
validation-timeout: 18800
spring:
data:
mongodb:
uri: mongodb://data-flow:[email protected]:27017/data-flow
redis:
port: 6380
password: 58603924715
lettuce:
pool:
max-idle: 8
min-idle: 1
max-active: 10
host: 127.0.0.1
data-flow:
server:
# 是否启用kafka监听
enable-kafka: true
# 推送至kafka的消息类型, 支持canal(二进制压缩)消息, ogg(JSON字符串)消息, 原生SourceEntity(JSON字符串)消息
kafka-msg-type: canal
# kafka监听配置, 由于canal、OGG只有库表信息, 所以此处只能通过库名和表名做过滤, 支持正则表达式
listen-table-config:
- schema: .*
tables:
- .*
- schema: capital
tables:
- zfpt_capital_order
- zfpt_capital_repayment_plan
- schema: auto_core_sys
tables:
- auto_core_order
- schema: zion
tables:
- loan_invoice_info
- repay_plan
- schema: mobile_card
tables:
- mcc_consume_repayment
- mcc_consume_supply
- mcc_customer_consume
- mcc_virtual_order_transaction
- schema: o2o
tables:
- appreciation_service
- pl_repayment_plan_capital
- pl_repayment_plan_user
# 监听源端消息的kafka配置, 若enable-kafka为false则无需配置
kafka:
consumer:
properties:
bootstrap-servers: localhost:9092
group-id: local
enable-auto-commit: false
auto-commit-interval-ms: 1000
session-timeout-ms: 15000
## auto-offset-reset: earliest
max-poll-records: 1
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
container:
topics:
- example
ack-mode: MANUAL
enable-http-invoke: true
# 导出数据的MQ配置, 暂时支持kafka和Rocket, 如未使用到可不配置
mq-instances:
- name: example_sink # 此MQ实例的名称, 在flow配置中通过此名称使用
type: kafka # MQ类型(kafka, rocket)
# MQ属性配置, 参考kafka, rocket的构造参数
properties:
bootstrap-servers: localhost:9092
group-id: data-flow
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
- name: to_rocket
type: rocket
properties:
name-serv: localhost:8088
group-id: test
server:
servlet:
context-path: /data-flow
port: 10022
- _id string
flow名称, 同时也作为mongo存储主键- source string
flow对应的source名称, 若没有source名称需设置为空字符串- schema string
flow对应的schema- name string
flow对应的name- node_list list 流中的节点配置
- node_name string
节点名称, 同一个流中不可重复- eval_context list
表达式计算环境, 用于补充数据, 可为空, 可以有多个, 有序, 前一个变量的值也可为下一个变量定义所用
- name string
变量名称, 用于在之后使用- sql string
SQL语句, 如果提供该配置, 则此变量的值为SQL语句的查询结果, 使用${}书写表达式在SQL语句中引用已知数据- type string
指明SQL的查询结果类型: list(多条查询结果)或map(单条查询结果)- data_source string
指明SQL查询所使用的数据源, 如不配置则默认为master数据源- expression string
SPEL表达式, 如果配置了该项则忽略SQL配置, 表达式的计算结果作为该变量的值- on_condition string
SPEL表达式, 返回值应为bool值, 用于指明在何种条件下才加载该变量, 如无可不配置- simple_copy_fields boolean
是否将输入entity的字段全部直接复制到结果entity- skip_if_exception boolean
是否忽略异常- simple_convert object
简单的字段转换, 配置对象中的key为结果entity的字段名称, value为一个SPEL表达式, 表示- additional_expression list
附加表达式, 数组类型, 数组中的每一个元素为一个SPEL表达式(string), 可用以执行任意表达式- conditional_expression list
按条件执行的表达式, 每一项为一个object类型, condition字段为条件表达式, expression为该条件所要执行的表达式, expression也可以继续为一个object类型的条件配置
示例:{ "conditional_expression": [ { "condition": "true", "expression": [ "@service()", { "condition": "false", "expression": "[field2] = [var1] * 10" } ] } ] }- export_to_rdb object
将当前结果数据导出至关系型数据库
- method string
数据导出方式, 可选值:
- upsert: 当该条数据已经在数据库中存在时更新, 若不存在则插入
- insert: 直接插入
- target_data_source string
目标数据源名称, 不设置默认为master- target_schema string
目标库名, 必须指定- target_table string
目标表名, 必须指定- find_original object
upsert方式下查询旧数据的配置
- match_fields list
指定主键字段, 查询时会以这些字段为WHERE条件进行查询, 且这些字段必须在结果实体中存在- sql string
自定义查询旧数据的SQL, 使用${}书写表达式引用参数, 此配置将覆盖match_fields配置项- update object
- match_fields list
指定主键字段, 查询时会以这些字段为WHERE条件进行查询, 且这些字段必须在结果实体中存在- sql string
自定义查询旧数据的SQL, 使用${}书写表达式引用参数, 此配置将覆盖match_fields配置项- custom_fields object
自定义SQL字段- insert object
数据插入的配置,- export_to_mq object 将当前数据导出至MQ
- data string
SPEL表达式自定义导出数据, 不使用默认的结果数据
配置示例:
{
"_id" : "save_spider_result_flow",
"source" : "__default",
"name" : "weibo_spider",
"schema" : "weibo_spider",
"node_list" : [
{
"node_name" : "just_save",
"eval_context" : [],
"simple_copy_fields" : true,
"skip_if_exception" : false,
"resolve_order" : [
"filter",
"eval_context",
"simple_copy_fields",
"simple_convert",
"additional_expression",
"conditional_expression"
],
"filter" : "[nickname]==null",
"conditional_expression" : [
{
"condition" : "[user_id] == null or [user_id] == ''",
"expression" : "#res[user_id]=-1"
}
],
"export_to_rdb" : {
"method" : "upsert",
"target_schema" : "weibo",
"target_table" : "weibo_spider_result",
"target_data_source" : "master",
"sql_log" : true,
"find_original" : {
"match_fields" : [
"id"
]
},
"update" : {
"match_fields" : [
"id"
]
},
"insert" : {}
}
},
{
"node_name" : "save_to_news",
"resolve_order" : [
"filter",
"eval_context",
"simple_copy_fields",
"simple_convert",
"additional_expression",
"conditional_expression"
],
"eval_context" : [
{
"name" : "user_info",
"data_source" : "common",
"sql" : "SELECT * FROM common.weibo_user WHERE id=${[user_id]}",
"type" : "map"
}
],
"simple_convert" : {
"id" : "[id]",
"content" : "[content]",
"create_time" : "new java.util.Date()",
"send_account" : "[user_info][nickname]",
"title" : "#takeFrom([content], '【', '】')"
},
"conditional_expression" : [
{
"condition" : "[content] != null and (#res[title]==null or #res[title]=='')",
"expression" : [
{
"condition" : "[content].indexOf('#') != [content].lastIndexOf('#')",
"expression" : "#res[title]=[content].replaceAll(\".*#(.+?)#.*\", \"$1\")"
}
]
}
],
"export_to_rdb" : {
"method" : "upsert",
"target_schema" : "common",
"target_table" : "news",
"target_data_source" : "common",
"sql_log" : true,
"find_original" : {
"match_fields" : [
"id"
]
},
"update" : {
"sql" : "UPDATE common.news SET title='${#res[title]}', send_account='${#res[send_account]}', content='${#res[content]}', update_time=NOW() WHERE id='${[id]}'",
"match_fields" : [
"id"
]
},
"insert" : {
"sql" : "INSERT INTO common.news VALUES('${#res[id]}', '${#res[title]}', '${#res[content]}', '${#res[send_account]}', '${#formatDate(#res[create_time], \"yyyy-MM-dd HH:mm:ss\")}', NOW())"
}
}
},{
"node_name": "to_kafka",
"export_to_mq":{
"mq_name": "example_sink",
"mq_type": "kafka",
"topic": "news"
}
}
]
}将data-flow-server/src/main/docker目录下的文件复制到docker运行目录,根据自己的环境修改config目录下的application.yml和logback.xml文件,使用如下命令创建容器并启动:
docker-compose -p data-flow-cluster up有能力者亦可根据自己需求修改部署配置
演示模块,可直接启动,不依赖额外的中间件,flow配置采用文件存储方式,可在resources目录下看到。
前端模块,用于项目监控以及配置管理等。

(使用IDEA生成的类图, 布局可能不是太好)

- 流(Flow)
数据流, 一条流中可包含多个节点, 数据会一一经过这些节点去处理, 除第一个节点外, 其余每一个节点的输入都是上一个节点的输出, 在每个节点中, 都可以访问到原始数据(SourceEntity), 都可以进行转换、服务调用、导出操作,多个流之间互不干扰, 一条数据可并行进入多个流处理 - SourceEntity(ink.andromeda.dataflow.core.SourceEntity)
原始数据的抽象, 所有输入的数据都需要转换为SourceEntity, 字段及含义如下:id: long类型, 保留字段, 暂未使用到key: String类型, 业务含义的主键, 保留字段, 暂未使用到source: String类型, 源名称, 一般对应于一个数据源实例schema: String类型, 一般指数据库名称name: String类型, 一般指表名称data: Map<String, Object>类型, 数据的载体before: Map<String, Object>类型, 在canal, ogg场景下当前数据的上一状态timestamp: long类型, 数据的发送时间戳opType: String类型, 数据的更新类型, 例如UPDATE,DELETE,INSERT
说明: source, schema, name也可视使用场景不同而赋予其他意义, 默认的描述含义是在关系型数据库的同步的场景下。
- TransferEntity(ink.andromeda.dataflow.core.TransferEntity)
数据在数据流节点中转化时的中间结果, 字段含义与SourceEntity类似
项目的大部分Bean采用Spring的Conditional机制加载,此处介绍的类如果标记为Spring Bean,则表明是被Spring管理的,若有特殊需求,可以通过在Spring Java Configuration注册Bean实例的方式覆盖默认实现。
-
DataFlowManager(ink.andromeda.dataflow.core.flow.DataFlowManager) spring bean
流的管理服务, 接口方法:List<DataFlow> getFlow()获取所有的flowList<DataFlow> getFlow(String source, String schema, String name)根据传入的source,schema,name获取对应的流@Nullable DataFlow getFlow(String flowName)根据名称获取流default DataFlow getFlow(String source, String schema, String name, String flowName)根据传入的source、schema、name以及流的名称获取流,如果流的名称在全局不唯一的时候,但我认为flow的名称是唯一的(同时作为了mongo主键字段),因此作为保留方法,暂未使用到。void reload()重新加载所有的流,应用于流配置或者实例是缓存在内存中而非实时获取的时候,下面几个重载的reload也是同样的使用场景。void reload(String source, String schema, String name)根据source、schema、name重新加载。void reload(String flowName)根据flow名称重新加载。default void reload(String source, String schema, String name, String flowName)根据source、schema、name以及flow名称重新加载,该方法与同签名的getFlow方法一样,作为一个保留方法。
本接口有一个抽象的实现:
ink.andromeda.dataflow.core.flow.ConfigurableDataFlowManager,此抽象方法实现了从flow配置实例化DataFlow的部分,子类需实现json配置增删改的接口。默认实现类为
ink.andromeda.dataflow.core.flow.DefaultDataFlowManager,使用Mongo数据库存储配置文件,依赖于DefaultDataFlow和ConfigurableFlowNode,后面会介绍到。 -
DataFlow(ink.andromeda.dataflow.core.flow.DataFlow) 流的抽象, 继承于
ink.andromeda.dataflow.core.Registry<FlowNode>,即继承了对FlowNode进行管理的一系列方法,主要方法为:default String getApplySource()获取此流所匹配的source名称,默认空字符串default String getApplySchema()获取此流所匹配的schema名称,默认空字符串。default String getApplyName()获取此流所匹配的(表)name,默认空字符串。String getName()获取流的名称。List<FlowNode> getNodes()获取此流中所包含的节点。default TransferEntity inflow(SourceEntity sourceEntity) throws Exception处理一条数据,默认实现为遍历所有节点,然后返回最后一个节点的处理结果。
默认的子类实现为
ink.andromeda.dataflow.core.flow.DefaultDataFlow,较为简单。 -
FlowNode(ink.andromeda.dataflow.core.node.FlowNode)
流中的一个节点的抽象,方法default String getName()获取节点名称。TransferEntity apply(SourceEntity source, TransferEntity input) throws Exception处理数据,source为原始的数据(刚开始进入流的时候的数据),input为前一个节点的输出。default TransferEntity apply(SourceEntity sourceEntity) throws Exception处理数据,当前节点为第一个节点的时候用到,默认实现为:default TransferEntity apply(SourceEntity sourceEntity) throws Exception { return apply(sourceEntity, TransferEntity.builder() .data(sourceEntity.getData()) .name(sourceEntity.getName()) .opType(sourceEntity.getOpType()) .schema(sourceEntity.getSchema()) .source(sourceEntity.getSource()) .build()); }
default FlowNode then(FlowNode node)用于聚合多个FlowNode,默认实现代码:default FlowNode then(FlowNode node){ return (source, input) -> node.apply(source, FlowNode.this.apply(source, input)); }
默认的实现类为
ink.andromeda.dataflow.core.node.ConfigurableFlowNode,此类根据配置进行数据处理,依赖于ink.andromeda.dataflow.core.SpringELExpressionService(SpringEL表达式解析)和DefaultConfigurationResolver(配置解析器)。 -
DefaultConfigurationResolver(ink.andromeda.dataflow.core.node.resolver.DefaultConfigurationResolver)
配置解析器,此类是一个抽象类,实现ink.andromeda.dataflow.core.node.resolver.ConfigurationResolver<Void>接口,主要服务于ConfigurableFlowNode类。public abstract String getName()获取配置项名称,与Node配置中的key对应一致。public abstract void resolve(SourceEntity source, TransferEntity input, TransferEntity target, @Nullable Object config, Map<String, Object> rootData) throws Exception解析处理数据,入参分别为source(原始数据)、input(节点的入参)、target(处理结果所应保存的对象)、config(配置项的值)、rootData(解析过程中的变量)。
默认实现有
AdditionalExpressionResolver、ConditionalExpressionResolver、EvalContextResolver、ExportToMQResolver、ExportToRDBResolver、FilterResolver、SimpleConvertResolver、SimpleCopyFieldsResolver,分别处理不同的配置项。如果有新的解析器需要加入,获取name=flowNodeResolver,type=Registry<DefaultConfigurationResolver>的Spring Bean后,通过add方法注册解析器即可。 -
DataRouter(ink.andromeda.dataflow.core.DataRouter) spring bean
路由器,将数据根据元信息路由到不同的流进行处理。DataFlowManager getDataFlowManager()获取流管理器。void setDataFlowManager(DataFlowManager dataFlowManger)设置流管理器。List<DataFlow> route(SourceEntity sourceEntity)根据SourceEntity,返回对应需要处理该数据的所有流。default List<TransferEntity> routeAndProcess(SourceEntity sourceEntity) throws Exception路由并处理输入数据,返回每一个流处理的结果。
默认实现为
ink.andromeda.dataflow.core.DefaultDataRouter,路由策略为简单的进行source、schema、name的字段匹配,route方法代码如下:@Override public List<DataFlow> route(SourceEntity sourceEntity) { List<DataFlow> flowList = dataFlowManager.getFlow( sourceEntity.getSource(), sourceEntity.getSchema(), sourceEntity.getName()); if (flowList.isEmpty()) { log.info("source: {}, schema: {}, name: {} cannot be routed to at least one flow", sourceEntity.getSource(), sourceEntity.getSchema(), sourceEntity.getName()); } else { log.info("be routed to flow: {}", flowList.stream().map(DataFlow::getName).collect(Collectors.joining(","))); } return flowList; }
routeAndProcess方法为匹配到的多个流并行处理,代码如下:
@Override public List<TransferEntity> routeAndProcess(SourceEntity sourceEntity) throws Exception { List<TransferEntity> transferEntities = new ArrayList<>(8); // 父级traceId String parentTraceId = Optional.ofNullable(MDC.get("traceId")).orElse(shortTraceId()); MDC.put("traceId", parentTraceId); log.info("starting process source entity: {}", sourceEntity); List<DataFlow> flowList = route(sourceEntity); CountDownLatch countDownLatch = new CountDownLatch(flowList.size()); for (DataFlow flow : flowList) { // 子traceId,在一个flow处理过程中唯一,方便日志追踪 MDC.put("traceId", parentTraceId + "-" + shortTraceId()); executorService.submit(() -> { try { transferEntities.add(flow.inflow(sourceEntity.clone())); }catch (FilteredException e){ log.info(e.getMessage()); }catch (Exception e) { log.error(e.getMessage(), e); }finally { countDownLatch.countDown(); } }); MDC.remove("traceId"); } countDownLatch.await(); return transferEntities; }
此部分测试针对data-flow-server模块的功能性测试,需要提供kafka、redis、mysql、mongo等中间件服务(data-flow-demo模块仅为项目演示,使用H2数据库,无需其他中间件)。
- 数据源
本项目开发时所用的测试数据源来自开源项目: weiboSpider, 可在当前项目doc/test/test-data-provider下找到,使用此python程序爬取微博数据并向kafka推送,以此提供测试数据。也可通过其他方式。 - mysql测试库表结构
doc/test/test_table.sql,在mysql中执行即可 - flow配置
doc/test/mongo-test-backup-data,使用mongorestore命令恢复即可 - application.yml配置,包含所需各中间件的配置,根据自己的配置修改
doc/test/application.yml
-
测试方案:
使用代码生成大量随机数据插入MySQL表中,再使用canal监听此表,经过kafka发送到应用程序中进行消费。模拟场景为:有两张业务表,客户信息和客户交易流水,现在需要对这两张表需要做一个镜像同步,额外需要一张实时更新的用户详细信息表和一张用户交易统计表,每当有用户发生交易时进行更新,方便运营人员查看。
源表结构:
-- 用户表 create table if not exists customer ( id bigint auto_increment primary key, name varchar(20) not null, id_card varchar(18) not null, address varchar(100) not null, create_time datetime default CURRENT_TIMESTAMP not null ); -- 用户流水 create table if not exists customer_transaction_log ( id bigint auto_increment primary key, customer_id bigint not null, amount decimal(18, 2) not null, transaction_time datetime default CURRENT_TIMESTAMP null );
目标表结构:
-- 用户信息统计 create table if not exists customer_consume_info ( id bigint auto_increment comment '用户id' primary key, last_consume_amount decimal(18, 2) default 0.00 null comment '最近一次消费金额', last_consume_time datetime null comment '最近一次消费时间', total_consume_amount decimal(18, 2) default 0.00 null comment '总消费金额', current_month_consume_amount decimal(18, 2) default 0.00 not null comment '当月消费金额', current_year_consume_amount decimal(18, 2) default 0.00 not null comment '当年消费金额' ); -- 用户详情 create table if not exists customer_detail ( id bigint auto_increment primary key, real_name varchar(20) not null, birthday date not null, gender smallint not null, area varchar(6) not null, home_address varchar(100) default '' not null, id_card char(18) not null ); -- 用户表镜像 create table if not exists origin_customer ( id bigint auto_increment primary key, name varchar(20) not null, id_card varchar(18) not null, address varchar(100) not null, create_time datetime default CURRENT_TIMESTAMP not null ); -- 用户交易表镜像 create table if not exists origin_customer_transaction_log ( id bigint auto_increment primary key, customer_id bigint not null, customer_name varchar(20) not null, amount decimal(18, 2) not null, transaction_time datetime default CURRENT_TIMESTAMP null );
flow配置:
同步用户和用户详情,此配置将输出两个结果到数据库
{ "_id": "data_flow_mock_customer", "source": "__default", "schema": "data_flow_mock_src", "name": "customer", "node_list": [ { "node_name": "to_origin", "eval_context": [], "simple_copy_fields": true, "skip_if_exception": false, "export_to_rdb": { "method": "upsert", "target_schema": "data_flow_mock_sink", "target_table": "origin_customer", "find_original": { "match_fields": [ "id" ] }, "update": { "match_fields": [ "id" ] }, "insert": {} } }, { "node_name": "to_customer_detail", "simple_convert": { "id": "[id]", "real_name": "[name]", "id_card": "[id_card]", "birthday": "[id_card].substring(6,14)", "gender": "T(Integer).parseInt([id_card].charAt(16)) % 2", "area": "[id_card].substring(0, 6)", "home_address": "[address]" }, "export_to_rdb": { "method": "upsert", "target_schema": "data_flow_mock_sink", "target_table": "customer_detail", "find_original": { "match_fields": [ "id" ] }, "update": { "match_fields": [ "id" ] }, "insert": {} } } ] }同步流水
{ "_id": "data_flow_mock_customer_trans_mirror", "source": "__default", "schema": "data_flow_mock_src", "name": "customer_transaction_log", "node_list": [ { "node_name": "to_origin", "eval_context": [ { "name": "customer", "sql": "SELECT * FROM data_flow_mock_src.customer WHERE id=${[customer_id]}", "type": "map" } ], "resolve_order": [ "filter", "simple_copy_fields", "eval_context", "simple_convert", "additional_expression", "conditional_expression" ], "simple_copy_fields": true, "skip_if_exception": false, "simple_convert": { "customer_name": "[customer][name]" }, "export_to_rdb": { "method": "upsert", "target_schema": "data_flow_mock_sink", "target_table": "origin_customer_transaction_log", "find_original": { "match_fields": [ "id" ] }, "update": { "match_fields": [ "id" ] }, "insert": {} } } ] }实时更新统计信息
{ "_id": "data_flow_mock_customer_consume_info", "source": "__default", "schema": "data_flow_mock_src", "name": "customer_transaction_log", "node_list": [ { "node_name": "node", "eval_context": [ { "name": "total_consume_amount", "sql": "SELECT SUM(amount) as sum FROM data_flow_mock_src.customer_transaction_log WHERE customer_id=${[customer_id]}", "type": "map" }, { "name": "current_month_consume_amount", "sql": "SELECT SUM(amount) as sum FROM data_flow_mock_src.customer_transaction_log WHERE customer_id=${[customer_id]} AND transaction_time > STR_TO_DATE(CONCAT(DATE_FORMAT(NOW(),'%Y-%m'), '-01'),'%Y-%m-%d');", "type": "map" }, { "name": "current_year_consume_amount", "sql": "SELECT SUM(amount) as sum FROM data_flow_mock_src.customer_transaction_log WHERE customer_id=${[customer_id]} AND transaction_time > STR_TO_DATE(CONCAT(DATE_FORMAT(NOW(),'%Y'), '-01-01'),'%Y-%m-%d')", "type": "map" } ], "resolve_order": [ "filter", "eval_context", "simple_copy_fields", "simple_convert", "additional_expression", "conditional_expression" ], "simple_copy_fields": false, "skip_if_exception": false, "simple_convert": { "id": "[customer_id]", "last_consume_amount": "[amount]", "last_consume_time": "[transaction_time]", "total_consume_amount": "[total_consume_amount][sum]", "current_month_consume_amount": "[current_month_consume_amount][sum]", "current_year_consume_amount": "[current_year_consume_amount][sum]" }, "export_to_rdb": { "method": "upsert", "target_schema": "data_flow_mock_sink", "target_table": "customer_consume_info", "find_original": { "match_fields": [ "id" ] }, "update": { "match_fields": [ "id" ] }, "insert": {} } } ] } -
硬件参数
CPU:Intel i5-1038NG7
内存:32GB -
软件版本
操作系统:macOS Big Sur 11.2.2
MySQL:8.0.21
Kafka:2.12-2.2.2
Java:11
docker-engine:20.10.2(canal、redis、mongo为docker环境) -
测试结果
单实例下运行这三个配置,平均速度约为250+条flow/s左右,受制于MySQL性能,刚开始数据库数据较小时速度很快,随着数据量急剧增大,速度也慢慢降低,处理速率主要在于flow配置的复杂度和数据库的性能,此测试作为参考。