{kind=link}
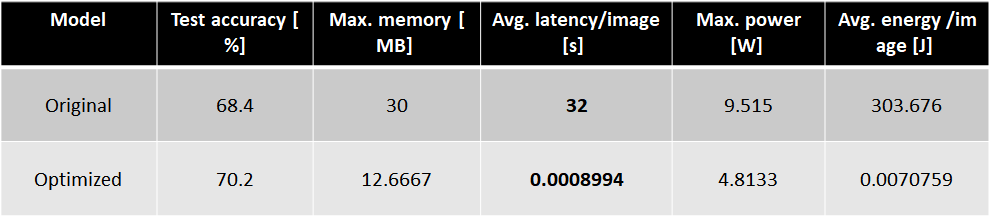
We utilized the "structural_pruning.py" to prune the initial Mobilenet and afterwads we used Knowledge Distillation to increase the accuracy of the pruned network. We used the following implementation found on github, and modified accordingly to support our case: https://github.com/peterliht/knowledge-distillation-pytorch We have also included the parts of the code we changed in the aforementioned framework: change the "knowledge_distillation.py", copy the cnn_distill directory to a new mobilenetv1_distill directory with "params.json" (inside the experiments directory), change the "data_loader.py" in model directory.
To test the accuracy on the entire dataset and the parameters of our network: $ python test_model_acc_params.py --model="optimum0.955_pruned_KD"
Then, we used the "convert_tf_int.py" to convert from PyTorch to TFlite, and also perform static quantization: $ python convert_tf_int.py --model="optimum0.955_pruned_KD"
Finally, to deploy on MC1: $ python deploy_tflite.py --model="optimum0.955_pruned_KDstat"